TelecomUral
Silver Member | Редактировать | Профиль | Сообщение | Цитировать | Сообщить модератору
оффтоп, я так думаю.
Цитата: zvezdochiot
Текст должен быть обработан и распознан. Иначе это не текст. |
Странное утверждение. С потолка взятое, пафосное и никчёмное.
на публ либ ру лежит книжка Трикоми 1957 года. Написано что обработка ваша.
Я занырнул в распознанный текст, и вижу вот такую ерунду.
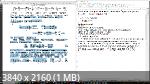
она же
https://disk.yandex.ru/i/UEQ1klJZpNO8Rw
И нафиг такое распознавание текста как "должное" - ? Должен - так вычитывайте. сигмы, границы ("rpanuua"), D, N, курсивный шрифт, это минимум к распознаванию. "иначе это не текст".
Не оффтоп.
По личному опыту, есть некоторая граница плохости скана (или оригинала), плюс конкретность информации (смысла черных значочков на бумаге), которую при бинаризации переходить не имеет смысла. В данном примере из ветки SK конечно можно чуть подтянуть по жирности бледные полосы, и ФР8 прекрасно тогда их распознает (проверил утром). В текстовой части. Но с формулами-то что делать - ?? В них нет ни символа избыточности, а значит хоть бинаризация хоть распознавание должны давать гарантию 100% попадания в исходный знак. Чего дать ничто, никакое потерьное преобразование, не может. Отсюда и граница "оставить серым". Давно стало понятным и единственно приемлемым решением. Я потому и ocr чаще всего и не делаю, и не приветствую, что если уж делать, то вычитывать, а это неприемлемые затраты. Необоснованные, точнее, если бинаризация проделана тщательно.
Конечно, от обработки хочется идеального оригинал-макета, но это тупая работа по набору всего текста с нуля. Никакого отношения к здешней теме. |
Всего записей: 3709 | Зарегистр. 15-07-2010 | Отправлено: 11:28 10-06-2025 | Исправлено: TelecomUral, 11:31 10-06-2025 |
|





 Предыдущие части:
Предыдущие части: