JFK2005

Silver Member | Редактировать | Профиль | Сообщение | Цитировать | Сообщить модератору
sergEO7905
При компиляции приложения Intel C++ встраивает в программу диспетчер, определяющий тип процессора и доступные наборы команд. При выполнении выбирается оптимальный вариант, обеспечивающий максимальную производительность. Да, "по умолчанию" процессоры AMD им не опознаются (т.е. программа выполняется без использования SIMD-инструкций). Но эта проблема легко решаема, см. сайт Агнера Фога.
И даже без применения векторных команд Intel лучше оптимизирует код, повышая производительность на любом процессоре.
Цитата:| бенчмаркосеки и писькомерщики вполне могут пастись в разнообразных профильных тестопрограммах |
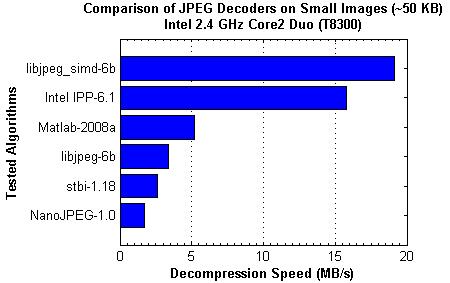
Причем здесь бенчмарки? Ну, будет декодироваться RAW или JPEG в 4 раза быстрее. Причем даже на старом Pentium 4, не говоря уж о новых процессорах. Пример: у меня когда-то был P4 2,4 ГГц. Смотреть HD-видео с применением обычных кодеков на нем было невозможно, не хватало мощности. С кодеками, оптимизированными под SSE2 - никаких проблем.
Всё дело, в том, что ALU, на которые вы так любите ссылаться, уже давно 128-разрядное (или даже 256-разрядное). Оптимальным образом оно будет работать, если выровнять данные по границе и загружать их в регистры сразу большими порциями, а не эмуляцией 32-разрядного режима. И как я уже выше говорил - на некоторых (реальных, из жизни) алгоритмах это дает аж 8-кратный прирост скорости.
Добавлено:
Skif_off
pi.cpp
Пример первый попавшийся, не самый удачный. Внутренний цикл компилятор трогать не стал, т.к. неизвестно количество итераций. Если там поставить парочку #pragma, алгоритм будет векторизован полностью.
Или вот такой пример.
vector.cpp |
Всего записей: 2060 | Зарегистр. 26-10-2005 | Отправлено: 17:38 07-01-2016 | Исправлено: JFK2005, 20:41 07-01-2016 |
|