Romul81

Advanced Member | Редактировать | Профиль | Сообщение | Цитировать | Сообщить модератору
Jonmey
Вы пользуетесь таким замечательным инструментом, как RegexBuddy, но, к сожалению, пока не освоили его в должной мере.
Всё нижеследующее я скажу не для того, чтобы поумничать, но только лишь с целью внести ясность и обратить ваше внимание на некоторые, неочевидные нюансы, связанные с рег. выражениями, учитывая, что вы, по всей видимости, являетесь человеком, активно ими интересующимся.
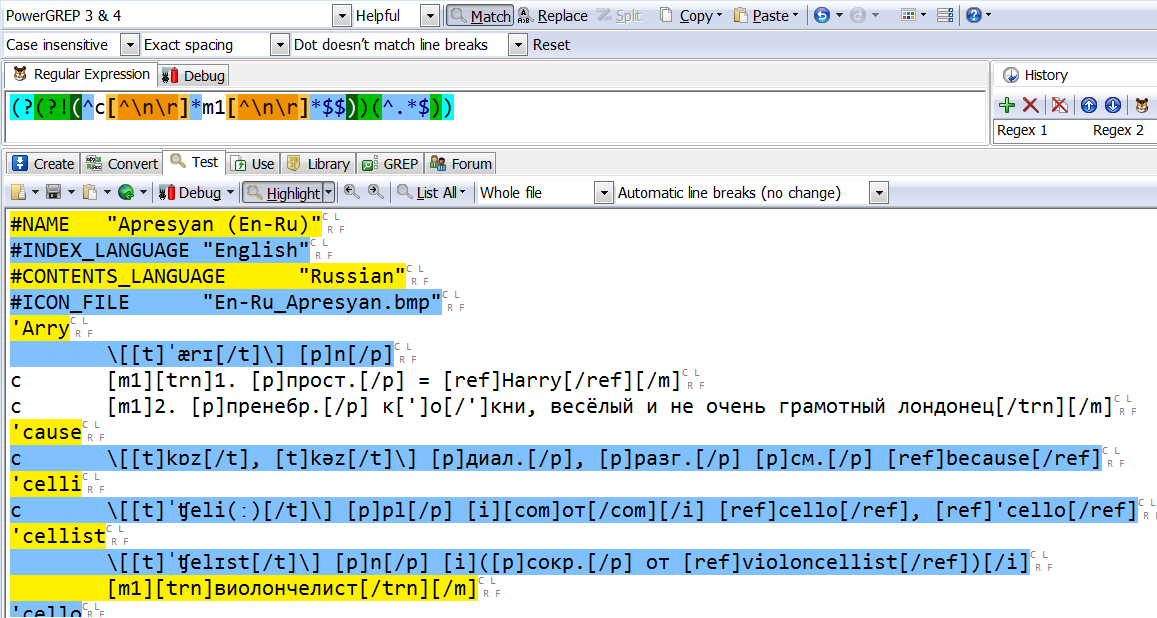
Ваша регулярка не делает главного - не отвечает заданному условию и находит не те совпадающие строки, что нужно. Объясню. Первоначальное условие было
Код:
Далее, было пожелание, чтоб вместо фильтра [^\n,] использовать "слово".
Т.е. логика следующая (fakecode)
Код:| line = начало строки + с И НЕ строка содержит "слово" И вся строка |
В вашем случае логика следующая:
Код:| line = ЕСЛИ впереди НЕ (начало строки + с + любые символы + "слово" + любые символы + конец строки) ТО вся строка |
Чувствуете разницу? На вашем же скриншоте есть строки, которые НЕ начинаются с C, поэтому не отвечают изначальному условию.
Далее. Вы в своём регулярном выражении используете УСЛОВИЕ (Condition).
Во-первых эта фича поддерживается далеко не везде. В том же AkelPad её нет, если не ошибаюсь. В JS точно нет. В JGSoft - да, есть.
Во-вторых, даже при наличии такой поддержки, использование условия является крайне редкой и специфической необходимостью, в реальной жизни редко встречающейся. Большинство регулулярок с условиями можно переписать на стандартный синтаксис без потери в функционале. Говорю из своего опыта. Мне очень хорошо знаком диалект JGSoft, т.к. я в своё время написал подсветку для EditPad для формата DSL. Там полностью всё на регулярках. И от использования условий я полностью отказался в какой-то момент за ненадобностью - вся логика реализуется и без них. От этого быстродействие (критический параметр для подсветки) только выигрывает.
Но предположим, что ваша логика верна и мы хотим составить рег.выражение её отрабатывающее. В данном случае, опять же, можно обойтись без условия и с выигрышем для производительности. Например так:
Код:
В чём выигрыш?
1) не используется условие
2) не захватываются группы
3) ДО "фильтра" \[m1\] - нежадный квантификатор для предотвращения множественного отката. После - жадный, чтоб захватить всё за один шаг.
4) на любой другой позиции, отличной от начала строки, регулярка фейлится с одним единственным бэктрэком (идеальная ситуация)
5) минимизирован повторный захват одного и того же контента.
Разница на практике. В следующей строке вашего примера:
Цитата:| c [m1]2. [p]пренебр.[/p] [trn]к[']о[/']кни, весёлый и не очень грамотный лондонец[/trn][/m] |
происходит закономерный фейл. По результатам дебаггера RegexBuddy, из позиции начала строки, ваша регулярка делает 199 шагов, прежде чем зафейлиться. Моя - 10 :)
На совпадающих строках производительность сопоставима, но моя быстрее где-то на 5-8% (это чисто по кол-ву шагов, не принимая во внимание наличие условия и захват групп).
Возвращаясь к первоначально поставленной задаче. Правильная регулярка для её решения:
Код:
------------------------
gerxer
Работает. Словарь Apresyan. Регулярка
Код:
фильтрует все заголовки, типа a la carte, a la francaise, оставляя только заголовки начинающиеся на a.
------------------------
YuS_2
Цитата:
Но почему правильнее?.. С точки зрения функционала - это то же самое (те же яйца, как говорится :)). Но я придерживаюсь паттерна, который присутствует в документации JGSoft. Там именно так. Да и короче. |
Всего записей: 1328 | Зарегистр. 03-03-2008 | Отправлено: 13:07 04-02-2019 | Исправлено: Romul81, 13:07 04-02-2019 |
|








 ?!word)[^\r\n])*$
?!word)[^\r\n])*$ 


